Setplex’s NORA Middleware.
Meet NORA: Setplex’s next generation Middleware. Cloud Native or On Prem, our microservice-oriented architecture allows us to scale on demand to meet the increasing needs of both enterprises looking to deliver OTT/IPTV globally and new streaming services that expect rapid growth.
Table of Contents
Microservice-oriented architecture design
A microservice-oriented architecture (MOA) incurs additional complexity in exchange for more flexibility. In a monolithic application, all the parts are in one box, so to speak. Therefore, you can declare dependencies ‘in-code’ and not worry too much about deployment issues. All the parts ship together at deployment time.

With an MOA, all the parts are distributed ‘across’ the network. Thus, you have to architect the microservices to work ‘in unison’, but at the same time, independently, to get the overall application up and running. The wiring involves identifying the network’s microservice(s) and enabling authorized access to all the microservices that make up the microservice-oriented architecture. The task includes providing credentials so the MOA can access each particular microservice and adjusting firewall and router settings at the physical level of the application’s operation.
As stated above, microservices offer more flexibility in terms of maintenance and upgrade, but that flexibility comes with the price of more complexity.
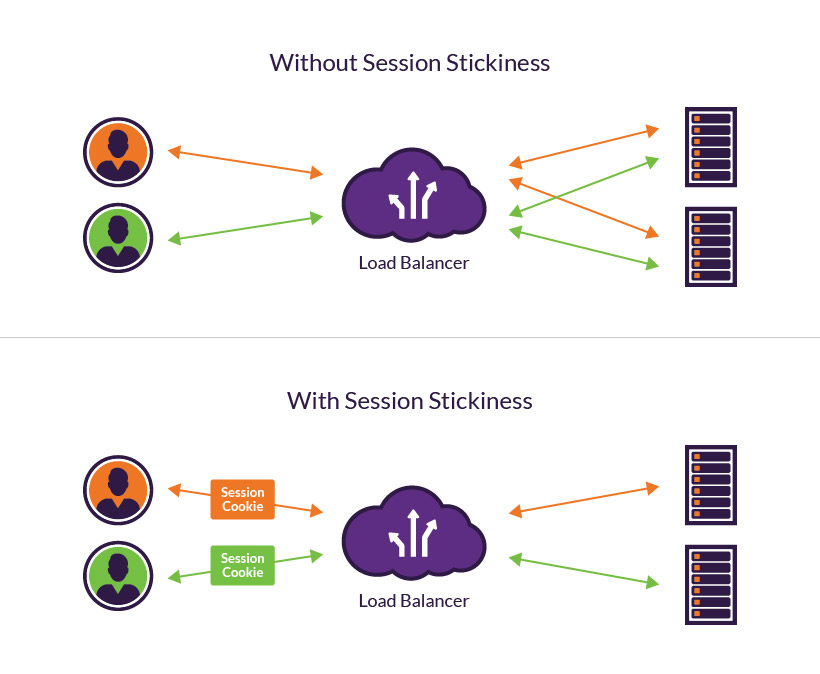
Load Balancing

Load balancing is a core strategy to create efficiencies in deploying an MOA.
Load balancing refers to efficiently distributing incoming network traffic across a group of backend servers, also known as a server farm or server pool.
A load balancer acts as the “traffic cop” sitting in front of your servers, routing client requests across all servers capable of fulfilling those requests in a manner that maximizes speed, capacity utilization and ensures that no single server is overtasked, which could degrade performance. If a single server goes down, the load balancer redirects traffic to the remaining online servers. When a new server is added to the server group, the load balancer automatically begins sending requests to it.
Load balancing can be performed at various layers in the Open Systems Interconnection (OSI) Reference Model for networking.
Layer 7 load balancing, which Setplex utilizes, is more CPU‑intensive than packet‑based Layer 4 load balancing, with the benefit of rarely causing degraded performance on a modern server. Layer 7 load balancing enables the load balancer to make smarter load‑balancing decisions, resulting in overall system optimization.
Session Storage
Session Storage is a great solution in which you do not store client sessions in the application itself, but in Session Storage. With that in place, we can open a session on any chosen node and all other system nodes will check client requests with the stored session and make changes independently. And microservices, made with 12-factor principles in mind, are completely stateless, which means they hold no data, so all the shared data has to be stored and fetched from outside of the application.
Kubernetes
The complexities introduced by a microservice-oriented architecture model require the use of container orchestration.
Fortunately, the complexities of creating, deploying, and supporting an MOA have revealed design patterns that have become well known over the years. In turn, these patterns have been used to create orchestration frameworks that are well suited to supporting MOAs. Probably the best known of these orchestration frameworks is Kubernetes, also known as K8s.
Kubernetes (K8s) is quite a technical achievement. Despite its complexity, this type of orchestration framework is necessary to run an MOA at scale. An MOA has many moving parts, and any one of them can fail at any time; therefore, to run a microservices-oriented application reliably, you need to incur the complexity of an orchestration framework.
K8s Architecture
Kubernetes (K8s) is the most widely used container orchestration tool. It is maintained by the community, orchestrates most of the microservices on the market and actually manages many cloud services.
The benefits offered by Kubernetes – and orchestration tools in general – include the following:
- High availability: applications have no downtime and are always accessible to the user.
- Self-healing. When a container fails or is unhealthy, Kubernetes replaces it automatically to maintain a desired state configuration and the overall health of the application.
- Declarative configuration management and version control. Kubernetes configurations are stored in YAML formatted files that can be version controlled with source control software, such as Git. The configurations can be applied to create or update resources.
- Multi-cloud and bare metal. Kubernetes enables IT teams to choose a cloud platform onto which to put workloads, such as Google Cloud Platform, Microsoft Azure, AWS or bare metal, so that they can avoid vendor lock-in.
- Service discovering and load balancing. Kubernetes exposes containers in pods, or groups of pods, using DNS or IP addresses so that other microservices can consume those resources.
- Scalability. When faced with high demand or an increase in load, Kubernetes horizontally scales the number of containers that run a microservice to avoid performance issues.
- Zero downtime. Kubernetes deployments create additional pods with a newly released image without destroying the existing containers, to ensure no downtime. Once the new containers are up and healthy, teams can roll out updates and delete old containers. If new containers fail, IT teams can roll back changes with minimal downtime.
With all of the above, K8s provides us a simple solution for supporting a very important feature of our system: the ability to be cloud agnostic, with the possibility of being deployed on private, public or even hybrid cloud solutions, as well as the ability to support any on-premise solutions.
Content Recommendation Engine
Setplex has invested heavily in a recommendation engine software, leveraging artificial intelligence and machine learning to provide consumers with ‘best in class’ content suggestions and discovery to increase user engagement, thus extending watch-time and reducing churn.
What sets our recommendation engine apart from the other ones in market?
- Recommendations are developed via ‘deep learning’ algorithms; by learning user interests and behavior, the platform recommends a collection of highly relevant and engaging content for each user.
- Our recommendations are updated on a daily basis and are served to consumers via simple suggestions on the home screen of our client apps.
- TV channel recommendation algorithms are based not only on which exact channels were watched, but at what time of day they were watched, as viewing patterns are key indicators of the actual content consumed (e.g. Nightly News at 10 PM versus light comedy in the evening).
- Content viewing times of ‘mini-duration’ (e.g. less than 10 seconds in the case of a TV channel) are not included in our recommendation algorithms, which keeps recommendations from being impacted by content that the viewer was not truly engaged with.
- Content is divided into 3 ‘type’ groups (Movie, TV show, TV channel). To illustrate, if a user typically views a lot of sports when watching TV channels, but virtually no sports-themed stand-alone movies, our content groupings prevent an inappropriate sports movie recommendation – since the user only watches sports as part of his/her TV channel viewing habits.
- Recommendations will include watch-times and choices made across ALL platforms on which a user has viewed content (e.g. Web, WebOS, iOS, tvOS, Android Phones). So, the recommendations made to a user when (s)he is on a SmartTV will be based, not only on that user’s prior SmartTV viewing, but will also consider her/his prior viewing on Mobile and Desktop applications.
How It Works
- The Engine collects and synthesizes viewing data from multiple perspectives, including;
- It collects and compares overall (all user) viewing habits with overall ‘all user’ habits on a device-by-device (SamsungTV, web, Android phone) basis.
- It dynamically groups users, based on their viewing consumption levels. In other words, it looks to find users that have similar levels of watch-time and group them together as one of many ways in which it creates recommendations.
- Within #2 above, it dynamically groups users, based on their historical content viewing habits and develops ‘viewing probabilities’ for each piece of content, thus creating ‘internal rankings’ within each user group.
- As a result, all content in our analytics database will have multiple ‘internal rankings’, each of which is associated with a different user group.
- Based on the ‘internal rankings’ within each user group, the Engine returns a list of recommended content that has not yet been viewed by the specific user, based on that group’s set of internal rankings.
In summary, our engine provides hyper-personalized content suggestions. By doing so, we transform historical customer viewing patterns into deep and enduring relationships that unlock a new level of growth for our clients.

2 Comments
David · October 13, 2022 at 5:02 am
I believe there are many more pleasurable opportunities ahead for individuals that looked at your site.
Joseph · October 14, 2022 at 9:07 am
Nice changes! Recommendation engine is truly what viewers look for on a video streaming platform